Deciphering Biosynthetic Gene Clusters with a Context-aware Protein Language Model
Deciphering Biosynthetic Gene Clusters with a Context-aware Protein Language Model
Kang, Z.; Zhang, H.; Liang, C.; Yang, R.; Ye, Y.; Bai, H.; Zhang, Y.; Ning, K.
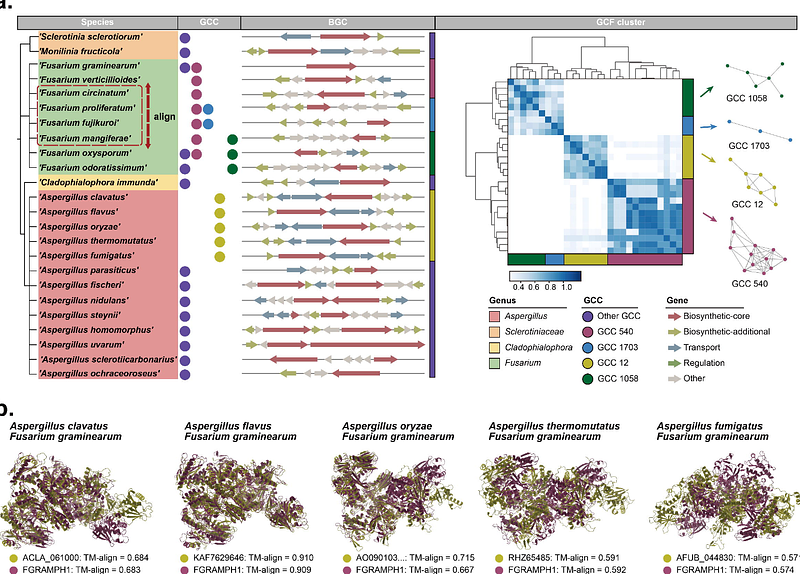
AbstractMicrobial secondary metabolites, synthesized by biosynthetic gene clusters (BGCs), play critical roles in ecological interactions and offer vast potential for biotechnological and pharmaceutical applications. Despite advances in computational BGC detection, current methods face challenges, including time-consuming sequence alignments, dependence on known homologs and manually defined rules, limiting its robustness and generalizability. To address these, we present CoreFinder, a deep learning framework that integrates protein language models (pLMs) and genomic contexts to predict product class and decipher gene functions within BGCs without alignment. CoreFinder demonstrated higher precision of 0.945 (842/891) and recall of 0.821 (842/1,025) than antiSMASH for core gene annotation in over 700 experimentally validated fungal BGCs. Built on CoreFinder, we introduced an end-to-end scalable workflow for BGC screening and deciphering, which is about 240 times faster than antiSMASH. Applied to 256 genomes spanning 197 taxa, CoreFinder identified 6,414 core genes within 4,585 BGCs. Further analysis indicates that a non-ribosomal peptide synthetase (NRPS) family likely existed prior to the divergence of Fusarium and Aspergillus and evolved into function-specific gene clusters. These findings emphasize the potential of CoreFinder as a powerful tool for accelerating natural product discovery and driving innovation in synthetic biology by unlocking novel biosynthetic pathways for biotechnological and pharmaceutical advancements.