On improving experimental binding affinity predictions with synthetic data
On improving experimental binding affinity predictions with synthetic data
Ryczko, K.; Zin, P. P.; Crivelli-Decker, J.; Le, L.; Jha, P. K.; Shields, B. J.; Lemos, P.; Bandi, S.; Van Damme, M.; Sood, A.; Huntington, L.; Pitman, M.; Ganahl, M.; Bortolato, A.
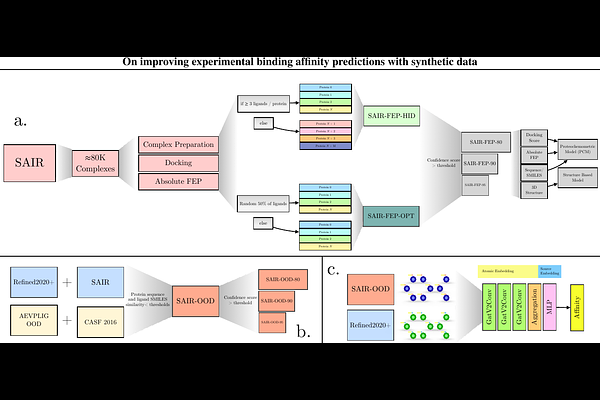
AbstractThe success of deep learning binding affinity prediction models depends critically on expanding experimental data with reliable synthetic data. We extend the Structurally Augmented IC50 Repository (SAIR) with {approx}80K absolute free energy perturbation (AFEP) calculations and present two distinct data splits, SAIR-FEP and SAIR-OOD (out-of-distribution), to simulate realistic drug discovery scenarios. We compare sequence-based proteochemometric (PCM) models and state-of-the-art, structure-based deep learning models and demonstrate that PCM models can be enhanced by physics-based descriptors. While structure-based deep learning methods capture finer geometric detail, their performance is highly sensitive to the input structure. By filtering for high-confidence, co-folded complexes, we show that the performance improves predictably, whereas training on all complexes blindly does not yield performance gains. Finally, using the SAIR-OOD split, we demonstrate that simultaneous training on synthetic and experimental data improves performance on publicly available, experimental benchmarks. These results provide a clear strategy for using synthetic data to advance experimental binding affinity predictions.