Interpretable Biological Sequence Clustering with iClust
Interpretable Biological Sequence Clustering with iClust
Zhang, S.; Liu, X.; Lou, J.; Jiang, M.; He, Z.
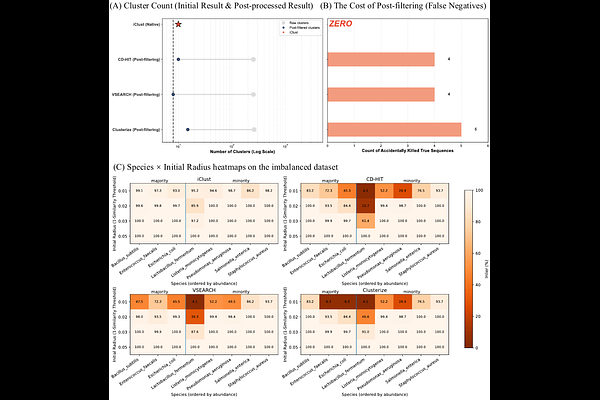
AbstractBiological sequence clustering is a fundamental problem in bioinformatics, yet most existing methods mainly optimize clustering quality or efficiency while offering limited insight into why sequences are grouped together. This restricts their usefulness in downstream analysis, where representative sequences and clear cluster boundaries are often needed. To address this issue, we propose iClust, an interpretable clustering method that characterizes each cluster by a representative prototype and an adaptive radius. By adapting to local sequence structure rather than relying on a single global threshold, iClust produces clusters that are both meaningful and explainable. A final consolidation step further reduces tiny fragments and improves structural stability. Experiments on simulated and real biological sequence datasets show that iClust achieves competitive clustering performance while providing clearer cluster-level explanations than conventional threshold-based methods. In addition to its empirical impact as a practical clustering method for biological sequences, this article opens up new avenues for developing biological sequence clustering approaches from the viewpoint of interpretable machine learning.