Canonical self-supervised pretraining paradigm constrains the capacity of genomic language models on regulatory decoding
Voice is AI-generated
Connected to paperThis paper is a preprint and has not been certified by peer review
Canonical self-supervised pretraining paradigm constrains the capacity of genomic language models on regulatory decoding
Liang, Y.-X.; Wang, Y.; Pan, W.-Y.; Chen, Z.-Y.; Wei, J.-C.; Gao, G.
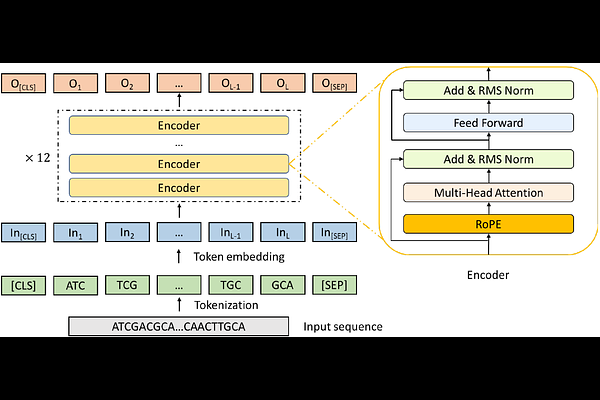
AbstractRecent studies suggest that genomic language models (gLMs) could help decode genomic regulatory code. Here, we systematically evaluated 11 representative gLMs across multiple regulatory genomics applications and found that current gLMs offer limited advantages over the random baseline. Further analysis revealed a systematic misalignment between the canonical sequence-only self-supervised pretraining paradigm and the context-specific dynamic nature of gene regulation, highlighting the need for function-oriented pretraining strategies that explicitly incorporate biochemical and regulatory priors.