Muon Learns More Robust and Transferable Features than Adam
Muon Learns More Robust and Transferable Features than Adam
Tianyu Ruan, Fengzhuo Zhang, Shuche Wang, Shihua Zhang
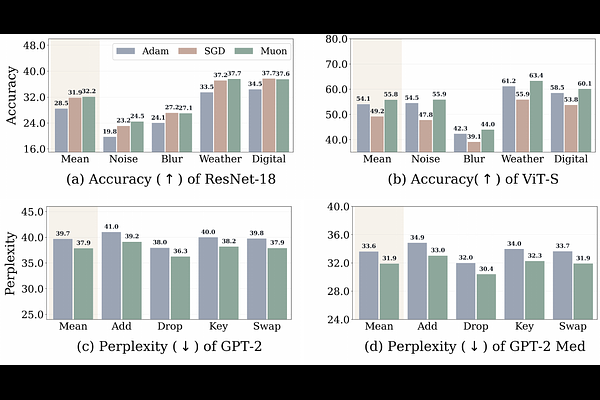
AbstractMuon has recently emerged as a state-of-the-art optimizer for pretraining Large Language Models (LLMs) and vision classifiers. Despite its efficiency advantage over Adam and SGD, the feature-learning advantage of Muon remains unclear. This paper investigates Muon's feature-learning advantage through the lens of robustness and transferability. First, by evaluating pretrained models on corrupted images and texts, we show that features learned by Muon are consistently more robust than those learned by Adam and SGD across different architectures, including transformers and Convolutional Neural Networks (CNNs). Using trained layer-wise probes, we further show that this robustness advantage is reflected in larger logit margins across layers. Second, by training linear classifiers or fine-tuning full models from pretrained parameters on downstream tasks, we demonstrate that Muon-learned features transfer more effectively than those learned by Adam and SGD. This transferability advantage is further supported by the diversity of hidden states across layers, as measured by effective rank. Finally, in a representative classification problem with multi-component features, we prove that Muon attains larger margins and higher effective rank than Adam and SGD, providing theoretical support for our empirical findings.