Diagnosing CFG Interpretation in LLMs
Diagnosing CFG Interpretation in LLMs
Hanqi Li, Lu Chen, Kai Yu
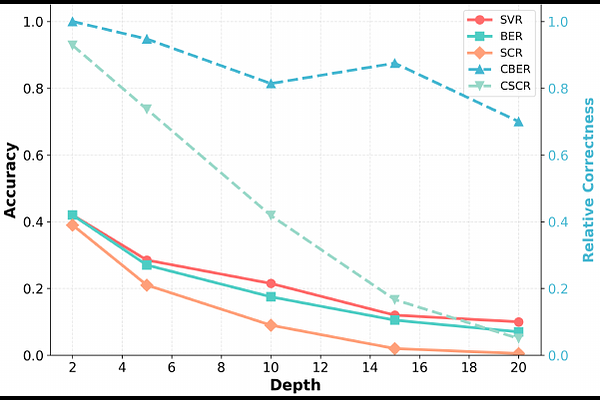
AbstractAs LLMs are increasingly integrated into agentic systems, they must adhere to dynamically defined, machine-interpretable interfaces. We evaluate LLMs as in-context interpreters: given a novel context-free grammar, can LLMs generate syntactically valid, behaviorally functional, and semantically faithful outputs? We introduce RoboGrid, a framework that disentangles syntax, behavior, and semantics through controlled stress-tests of recursion depth, expression complexity, and surface styles. Our experiments reveal a consistent hierarchical degradation: LLMs often maintain surface syntax but fail to preserve structural semantics. Despite the partial mitigation provided by CoT reasoning, performance collapses under structural density, specifically deep recursion and high branching, with semantic alignment vanishing at extreme depths. Furthermore, "Alien" lexicons reveal that LLMs rely on semantic bootstrapping from keywords rather than pure symbolic induction. These findings pinpoint critical gaps in hierarchical state-tracking required for reliable, grammar-agnostic agents.