Stream-CQSA: Avoiding Out-of-Memory in Attention Computation via Flexible Workload Scheduling
Stream-CQSA: Avoiding Out-of-Memory in Attention Computation via Flexible Workload Scheduling
Yiming Bian, Joshua M. Akey
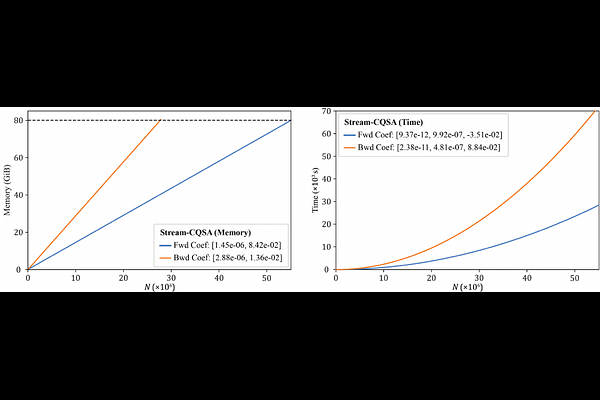
AbstractThe scalability of long-context large language models is fundamentally limited by the quadratic memory cost of exact self-attention, which often leads to out-of-memory (OOM) failures on modern hardware. Existing methods improve memory efficiency to near-linear complexity, while assuming that the full query, key, and value tensors fit in device memory. In this work, we remove this assumption by introducing CQS Divide, an operation derived from cyclic quorum sets (CQS) theory that decomposes attention into a set of independent subsequence computations whose recomposition yields exactly the same result as full-sequence attention. Exploiting this decomposition, we introduce Stream-CQSA, a memory-adaptive scheduling framework that partitions attention into subproblems that fit within arbitrary memory budgets. This recasts attention from a logically monolithic operation into a collection of schedulable tasks, enabling flexible execution across devices without inter-device communication. Experiments demonstrate predictable memory scaling and show that exact attention over billion-token sequences can be executed on a single GPU via streaming, without changing the underlying mathematical definition of attention or introducing approximation error.