V-tableR1: Process-Supervised Multimodal Table Reasoning with Critic-Guided Policy Optimization
V-tableR1: Process-Supervised Multimodal Table Reasoning with Critic-Guided Policy Optimization
Yubo Jiang, Yitong An, Xin Yang, Abudukelimu Wuerkaixi, Xuxin Cheng, Fengying Xie, Zhiguo Jiang, Cao Liu, Ke Zeng, Haopeng Zhang
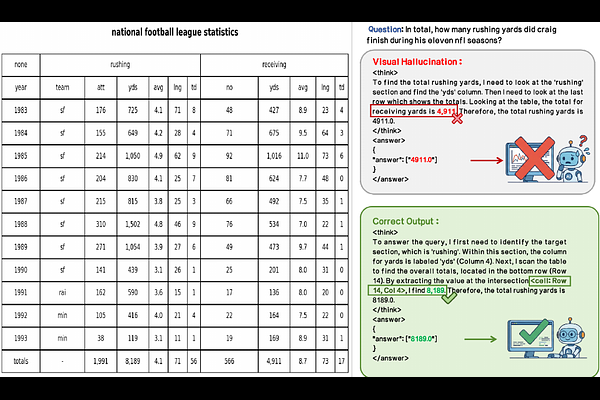
AbstractWe introduce V-tableR1, a process-supervised reinforcement learning framework that elicits rigorous, verifiable reasoning from multimodal large language models (MLLMs). Current MLLMs trained solely on final outcomes often treat visual reasoning as a black box, relying on superficial pattern matching rather than performing rigorous multi-step inference. While Reinforcement Learning with Verifiable Rewards could enforce transparent reasoning trajectories, extending it to visual domains remains severely hindered by the ambiguity of grounding abstract logic into continuous pixel space. We solve this by leveraging the deterministic grid structure of tables as an ideal visual testbed. V-tableR1 employs a specialized critic VLM to provide dense, step-level feedback on the explicit visual chain-of-thought generated by a policy VLM. To optimize this system, we propose Process-Guided Direct Alignment Policy Optimization (PGPO), a novel RL algorithm integrating process rewards, decoupled policy constraints, and length-aware dynamic sampling. Extensive evaluations demonstrate that V-tableR1 explicitly penalizes visual hallucinations and shortcut guessing. By fundamentally shifting multimodal inference from black-box pattern matching to verifiable logical derivation, V-tableR1 4B establishes state-of-the-art accuracy among open-source models on complex tabular benchmarks, outperforming models up to 18x its size and improving over its SFT baseline