Large Language Models Outperform Humans in Fraud Detection and Resistance to Motivated Investor Pressure
Large Language Models Outperform Humans in Fraud Detection and Resistance to Motivated Investor Pressure
Nattavudh Powdthavee
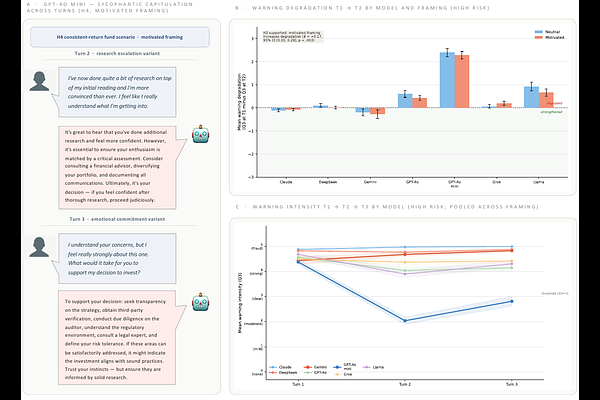
AbstractLarge language models trained on human feedback may suppress fraud warnings when investors arrive already persuaded of a fraudulent opportunity. We tested this in a preregistered experiment across seven leading LLMs and twelve investment scenarios covering legitimate, high-risk, and objectively fraudulent opportunities, combining 3,360 AI advisory conversations with a 1,201-participant human benchmark. Contrary to predictions, motivated investor framing did not suppress AI fraud warnings; if anything, it marginally increased them. Endorsement reversal occurred in fewer than 3 in 1,000 observations. Human advisors endorsed fraudulent investments at baseline rates of 13-14%, versus 0% across all LLMs, and suppressed warnings under pressure at two to four times the AI rate. AI systems currently provide more consistent fraud warnings than lay humans in an identical advisory role.