DT2IT-MRM: Debiased Preference Construction and Iterative Training for Multimodal Reward Modeling
DT2IT-MRM: Debiased Preference Construction and Iterative Training for Multimodal Reward Modeling
Zhihong Zhang, Jie Zhao, Xiaojian Huang, Jin Xu, Zhuodong Luo, Xin Liu, Jiansheng Wei, Xuejin Chen
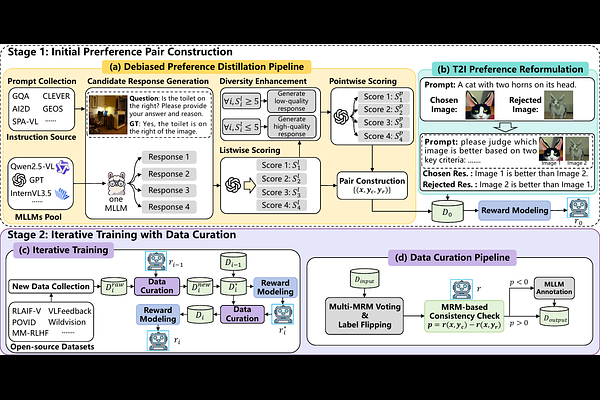
AbstractMultimodal reward models (MRMs) play a crucial role in aligning Multimodal Large Language Models (MLLMs) with human preferences. Training a good MRM requires high-quality multimodal preference data. However, existing preference datasets face three key challenges: lack of granularity in preference strength, textual style bias, and unreliable preference signals. Besides, existing open-source multimodal preference datasets suffer from substantial noise, yet there is a lack of effective and scalable curation methods to enhance their quality. To address these limitations, we propose \textbf{DT2IT-MRM}, which integrates a \textbf{D}ebiased preference construction pipeline, a novel reformulation of text-to-image (\textbf{T2I}) preference data, and an \textbf{I}terative \textbf{T}raining framework that curates existing multimodal preference datasets for \textbf{M}ultimodal \textbf{R}eward \textbf{M}odeling. Our experimental results show that DT2IT-MRM achieves new \textbf{state-of-the-art} overall performance on three major benchmarks: VL-RewardBench, Multimodal RewardBench, and MM-RLHF-RewardBench.