End-to-End Context Compression at Scale
End-to-End Context Compression at Scale
Ang Li, Sean McLeish, Haozhe Chen, Nimit Kalra, Zaiqian Chen, Artem Gazizov, Venkata Anoop Suhas Kumar Morisetty, Bhavya Kailkhura, Harshitha Menon, Zhuang Liu, Brian R. Bartoldson, Tom Goldstein, Sanae Lotfi, Micah Goldblum, Pavel Izmailov
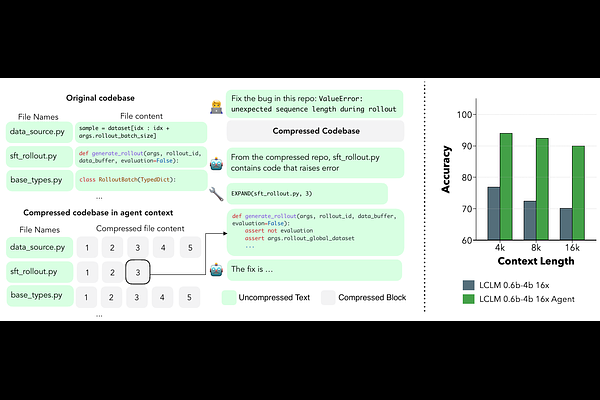
AbstractLong-context language model inference is bottlenecked by memory, as the KV cache grows with context length. Recent techniques to compress the KV cache fall short: they either degrade model quality substantially or require considerable time and compute to compress a single long prompt. Furthermore, many methods require the input to fit within the target model's context window, and are generally incompatible with modern production inference engines. Encoder-decoder compressors, which map a long token sequence to a shorter sequence of latent embeddings consumed by a decoder, are an appealing alternative in principle. However, existing approaches are not competitive with KV cache compression on the accuracy-efficiency frontier. In this work, we revisit encoder-decoder compression and close this gap. We first perform an architecture search, pre-training many variants from scratch to determine how best to design and train encoder-decoder compressors. Guided by our findings, we continually pre-train a family of 0.6B-encoder, 4B-decoder models on over 350B tokens each, at compression ratios of 1:4, 1:8, and 1:16. We introduce Latent Context Language Models (LCLMs), a family of compressors that improve the Pareto frontier across general-task performance, compression speed, and peak memory usage. We demonstrate that LCLMs serve as efficient backbones for long-horizon agents, letting the agent skim through a compressed long context and adaptively expand relevant segments on demand.