RAPO: Expanding Exploration for LLM Agents via Retrieval-Augmented Policy Optimization
RAPO: Expanding Exploration for LLM Agents via Retrieval-Augmented Policy Optimization
Siwei Zhang, Yun Xiong, Xi Chen, Zi'an Jia, Renhong Huang, Jiarong Xu, Jiawei Zhang
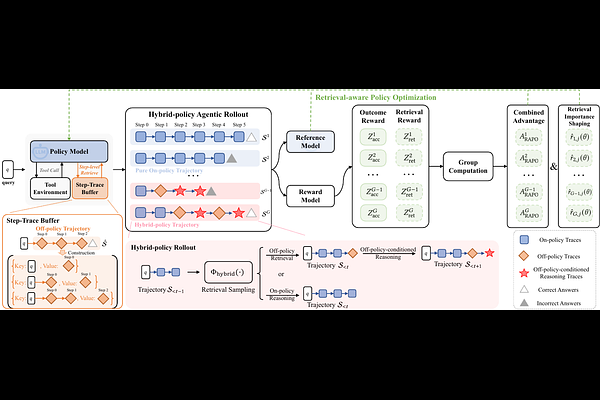
AbstractAgentic Reinforcement Learning (Agentic RL) has shown remarkable potential in large language model-based (LLM) agents. These works can empower LLM agents to tackle complex tasks via multi-step, tool-integrated reasoning. However, an inherent limitation of existing Agentic RL methods is their reliance on a pure on-policy paradigm for exploration, restricting exploration to the agent's self-generated outputs and preventing the discovery of new reasoning perspectives for further improvement. While recent efforts incorporate auxiliary off-policy signals to enhance exploration, they typically utilize full off-policy trajectories for trajectory-level policy estimation, overlooking the necessity for the fine-grained, step-level exploratory dynamics within agentic rollout. In this paper, we revisit exploration in Agentic RL and propose Retrieval-Augmented Policy Optimization (RAPO), a novel RL framework that introduces retrieval to explicitly expand exploration during training. To achieve this, we decompose the Agentic RL training process into two phases: (i) Hybrid-policy Agentic Rollout, and (ii) Retrieval-aware Policy Optimization. Specifically, we propose a Hybrid-policy Agentic Rollout strategy, which allows the agents to continuously reason over the retrieved off-policy step-level traces. It dynamically extends the reasoning receptive field of agents, enabling broader exploration conditioned on external behaviors. Subsequently, we introduce the Retrieval-aware Policy Optimization mechanism, which calibrates the policy gradient estimation with retrieval reward and importance shaping, stabilizing training and prioritizing retrieval-illuminating exploration. Extensive experiments show that RAPO achieves an +5.0% average gain on fourteen datasets across three agentic reasoning tasks, while delivering 1.2x faster training efficiency.