Algorithm for Contextual Queueing Bandits with Rate-Optimal Queue Length Regret
Algorithm for Contextual Queueing Bandits with Rate-Optimal Queue Length Regret
Seoungbin Bae, Dabeen Lee
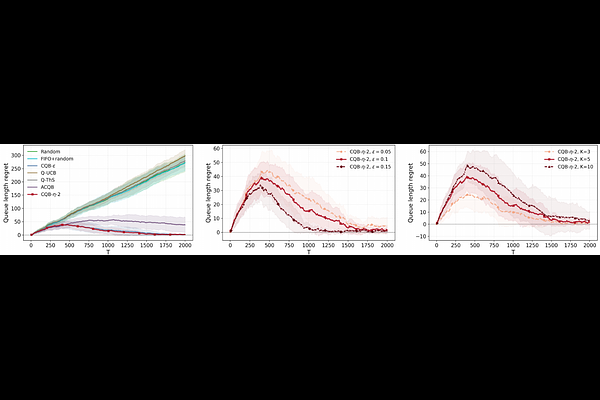
AbstractContextual queueing bandits provide a framework for learning to schedule heterogeneous jobs under unknown context-dependent service rates. Under stochastic contexts, existing algorithms achieve $\widetilde{\mathcal{O}}(T^{-1/4})$ queue length regret, defined as the expected difference between the learner's and oracle's queue lengths at horizon $T$. In this paper, we improve this rate to $\widetilde{\mathcal{O}}(T^{-1/2})$. The key observation is that random exploration is needed only up to a carefully chosen cutoff round, rather than throughout the entire horizon. We propose CQB-$η$-2, a three-phase algorithm: (i) pure random exploration to construct an initial estimator, (ii) $η$-random exploration combined with a UCB rule to continue learning while maintaining negative drift, and (iii) pure UCB after the exploration cutoff. Our proof decomposes the queue length regret at the cutoff round. Before the cutoff, negative drift suppresses queue length differences caused by suboptimal choices. After the cutoff, the first two phases provide sufficient random exploration samples, ensuring that UCB decisions incur small departure-rate gaps. Combining these two bounds yields queue length regret of order $\widetilde{\mathcal{O}}(T^{-1/2})$. We further prove a minimax lower bound of order $Ω(T^{-1/2})$. The proof constructs two hard instances that are statistically indistinguishable up to the final service decision, and uses a queue-specific coupling argument to convert the resulting testing error into queue length regret. Together, our upper and lower bounds characterize the minimax dependence on the horizon $T$ up to logarithmic factors.