GRASPrune: Global Gating for Budgeted Structured Pruning of Large Language Models
GRASPrune: Global Gating for Budgeted Structured Pruning of Large Language Models
Ziyang Wang, Jiangfeng Xiao, Chuan Xiao, Ruoxiang Li, Rui Mao, Jianbin Qin
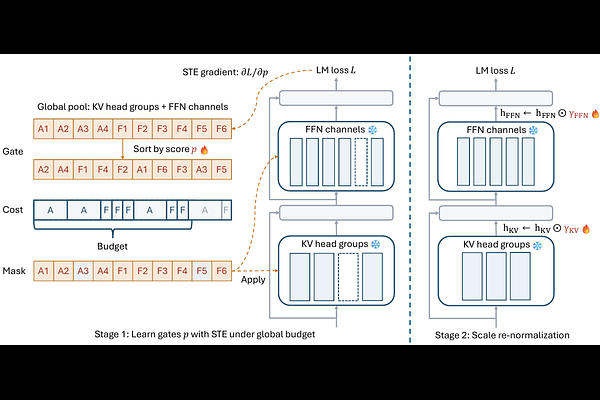
AbstractLarge language models (LLMs) are expensive to serve because model parameters, attention computation, and KV caches impose substantial memory and latency costs. We present GRASPrune, a structured pruning framework applied after pretraining that jointly prunes FFN channels and KV head groups under a single global budget. Instead of learning importance scores without constraints and applying the budget only after training, GRASPrune learns lightweight gate scores with a projected straight-through estimator that enforces a hard mask satisfying the budget at every step while keeping the backbone weights frozen. After the mask is fixed, we calibrate scaling factors on the retained units to mitigate scale mismatch caused by pruning, and fold these factors into the pruned weights to obtain a smaller dense checkpoint with no extra parameters at inference. On LLaMA-2-7B, GRASPrune removes 50% of parameters and achieves 12.18 perplexity on WikiText-2 while maintaining competitive average zero-shot accuracy on five benchmarks, using four epochs on 512 unlabeled calibration sequences on a single NVIDIA A100 80GB GPU without any full model fine-tuning.