Dissecting Quantization Error: A Concentration-Alignment Perspective
Dissecting Quantization Error: A Concentration-Alignment Perspective
Marco Federici, Boris van Breugel, Paul Whatmough, Markus Nagel
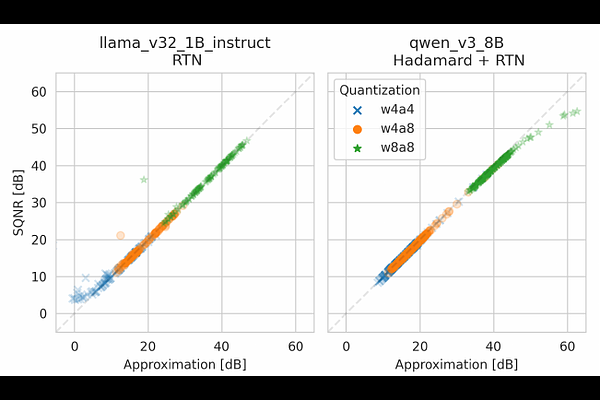
AbstractQuantization can drastically increase the efficiency of large language and vision models, but typically incurs an accuracy drop. Recently, function-preserving transforms (e.g. rotations, Hadamard transform, channel-wise scaling) have been successfully applied to reduce post-training quantization error, yet a principled explanation remains elusive. We analyze linear-layer quantization via the signal-to-quantization-noise ratio (SQNR), showing that for uniform integer quantization at a fixed bit width, SQNR decomposes into (i) the concentration of weights and activations (capturing spread and outliers), and (ii) the alignment of their dominant variation directions. This reveals an actionable insight: beyond concentration - the focus of most prior transforms (e.g. rotations or Hadamard) - improving alignment between weight and activation can further reduce quantization error. Motivated by this, we introduce block Concentration-Alignment Transforms (CAT), a lightweight linear transformation that uses a covariance estimate from a small calibration set to jointly improve concentration and alignment, approximately maximizing SQNR. Experiments across several LLMs show that CAT consistently matches or outperforms prior transform-based quantization methods at 4-bit precision, confirming the insights gained in our framework.